Showing off studying ML/ML - academic reels
[Reels] HyDE (Hypothetical Document Embedding)
BayesianBacteria
2024. 5. 2. 18:30
ACL 2023. 이긴 하지만 아카이브에는 2022에 올라왔음.
Super-simple background
- RAG (Retrieval Augmented Generation) is commonly used to complement the hallucination of LLMs.
- to find the proper documents (here, we call target document) for given queries, the "contriever" is used.
- the contriever can be an text-encoder model such as T5 or BERT.
- the target document can be searced with the encoded feature by the contriever via similarity search between query and such document.
Contribution of the paper
- to improve the accuracy of the document search with the encoded-feature, authors suggest a novel method HyDE : the input of the contriever is not only the query, but also the LLM-generated "possibly fake" answer.
- roughly speaking, semetic-distance (what ever it is) between (<query>, <document-answer>) is much closer than (<query, llm-answer>, <document-answer>).
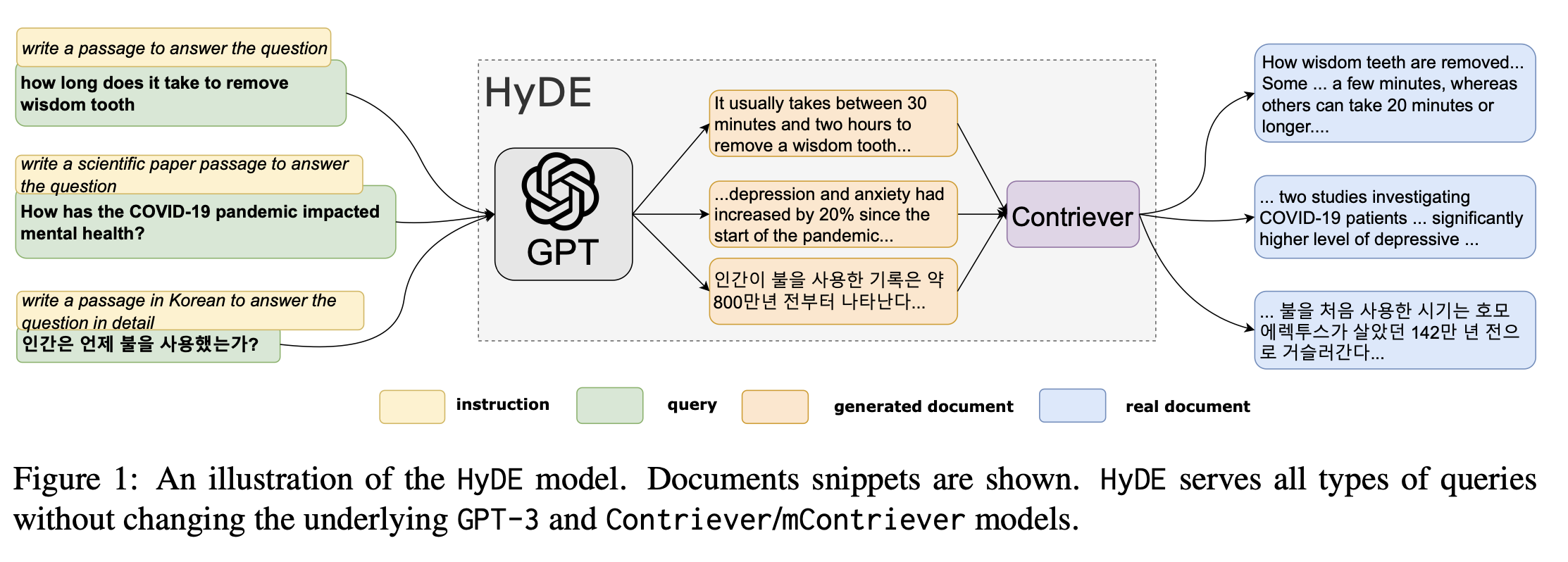
Opinion
- Consider the contriever was trained with the query-answer pair. If the model was perfectly trained and it well-generalizes, the HyPE-like method should not be improve the RAG performance.
- Therefore, success of the HyPE might imply that the current encoders for the contriever cannot convey the sementic information of the query-answer pairs (disclaimer: I do not know details about the encoders of the contriever and how to train them).
- (maybe) the similarity using such encoders, still, depends on due to how much structures of two prompts similar?