Showing off studying ML/ML - academic reels
[Reels] Imagen yourself
BayesianBacteria
2024. 10. 15. 21:49
Link , Personalized text-to-image generation by Meta AI
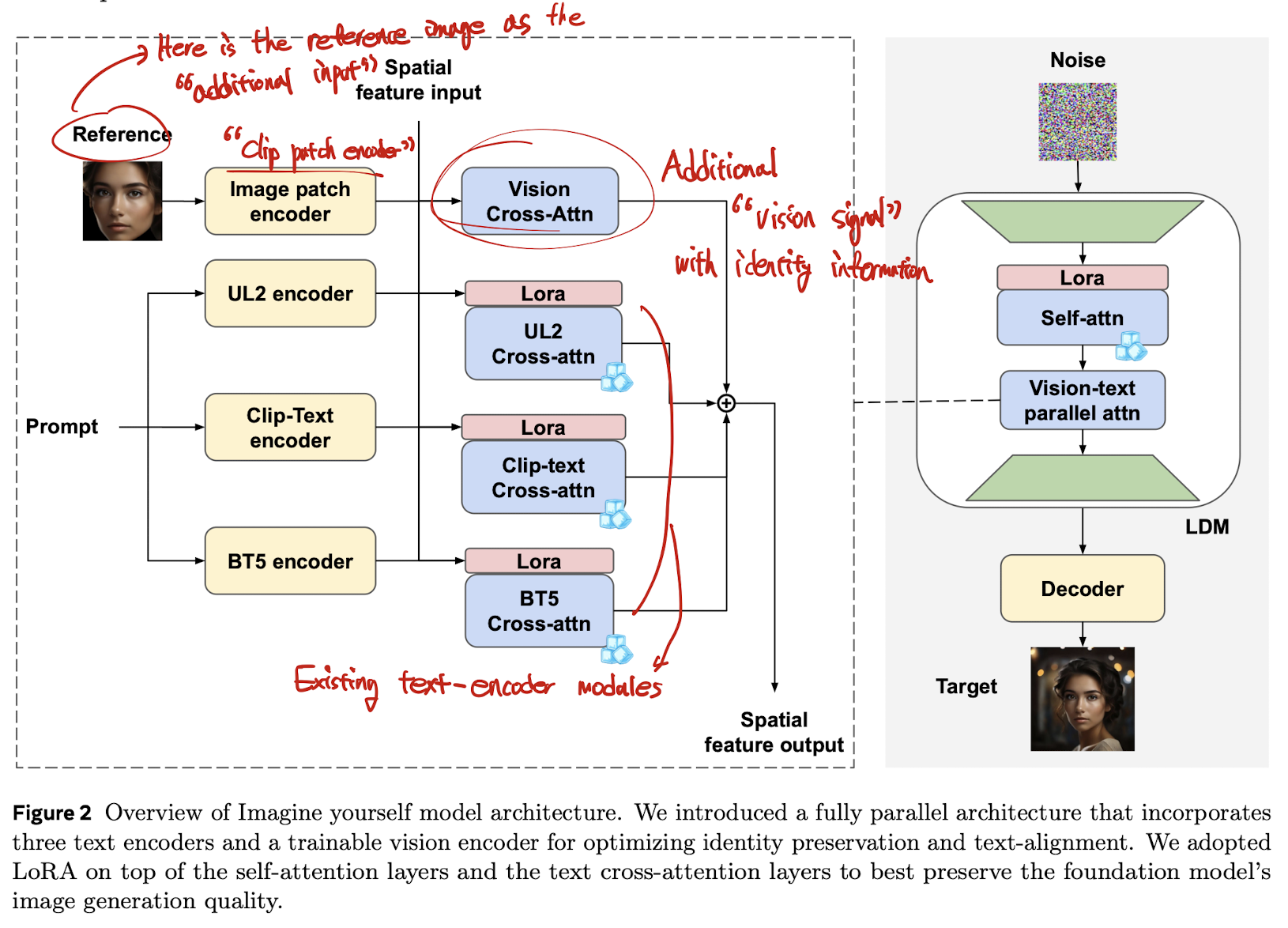
Insights
They create “architecture tailored for personalization image generation”
- they design kind of improved IP-adaptor for “any-personality” generation.
- therefore, the model does not need to be trained for a new subject, unlike LoRA or Dreambooth.
- meanwhile, other “any-personality generation models” could come with a strong over-fitting behavior such as copy-paste effect to the reference image. (it can be resolved in the synthetic pair dataset below)
Synthetic pair dataset for personalization task
- the limitation of the existing personalization task is “copy-paste” effect—the generated image looks super-similar to the given reference image.
- it means that the target generated image “does not follow” the given prompt.
- to resolve such issue, authors proposes the synthetic-data pipeline consisting of several real and synthetic data for one identity.
- sadly, the details of the pipeline is not included (such as, how to generate synthetic “personalized image”)
Rationale in their text encoders
- (common space between image and text) CLIP
- (encoding “characters”) ByT5: Byte-Level (Character-level) T5 architecture. (might improve the “text image” generation—for instance, the sign of “moreh is cool”)
- (Comprehending long and intricate text prompts) UL2: “improved T5”
Limitations
- only applicable for the models with cross-attention text conditioning.
- at least, from the proposed architecture in the paper
- to apply SD3-like architecture (w/o cross attentions), it need to be adjusted